XWeaver
This page gives a brief introduction to Aspect Oriented Programming (AOP). Readers should beware that AOP is a new and fast evolving field. Hence many of the considerations presented below may become rapidly obsolete. This applies in particular to the discussion of language support for AOP.
The same software application can be looked at from different perspectives and each perspective defines a model to represent the application. The term aspect designates one particular perspective and its associated model.
As an example, consider a real-time application. There are at least two obvious perspectives from which such an application can be considered: the functional perspective and the real-time perspective. The former perspective privileges the description of the algorithms and logic that are implemented by the application. A suitable model for it could be a UML class diagram that shows how the modules making up the application are organized and describing the functional behaviour that each of them implements. The real-time perspective of the application instead privileges its timing-related properties (execution times, timing distribution of its inputs, output deadlines, etc). A model describing this perspective might cover issues such as: the tasks making up the application, their scheduling policies, the synchronization mechanisms that are used to protect shared resources, etc. Each of these two perspectives defines an aspect and a model of the application.
An example of a less obvious type of aspect might be the algorithm optimization policy used in the application. If the application includes computationally intensive segments, it may make sense to define a general "optimization model" that might cover issues like: implementation of matrix operations, handling of sparse data structures, implementation of floating point operations, etc.
The error handling approach provides still another example of an aspect. If recording of run-time errors is important for an application, a model could be defined that describes which types of errors should be checked for and the actions that should be taken when errors are detected.
It should be stressed that there is no fixed set of aspects that is important for all applications. The aspects outlined above are just examples of potential aspects but, clearly, different applications have different concerns and therefore different sets of applicable aspects. The important point to note that, in order to capture the entire behaviour of an application, it will normally be necessary to consider several aspects. Traditional modelling and programming approaches have privileged the functional aspect but, except for trivial cases, this needs to be complemented with other aspects.
The AOP paradigm was introduced to help handle multiple aspects of an application. More specifically, AOP allows the principle of separation of concerns to be applied to all aspects of an application.
The principle of separation of concerns states that a model of an application should be organized as a set of lower level units where each unit encapsulates one particular feature of the application. The advantage of this approach is that the description of a feature is localized and is therefore more easily controllable. The problem addressed by AOP arises from the fact that application of the principle of separation of concerns to different aspects of the same application typically gives rise to organizations of the associated models that are difficult to map to each other. This is illustrated in the figure.
The figure shows two models (aspects) of the same application. Each model addresses a particular aspect of the application and each model is organized according to the principle of separation of concerns. This means that each model represents the application as a set of lower-level units (the small darker boxes). Since the two models are intended to represent the same application, there must exist some kind of mapping between them. Ideally, one would like this mapping to hold both at the level of the models themselves and at the level of the modular units into which the models are decomponed (i.e. one would like features that are encapsulated in a single modular unit in one model to be mapped to features that are encapsulated in a single modular unit in the other model). Unfortunately, this is usually not possible. The more normal situation is the one shown in the figure where a modular unit of model A is mapped to several modular units of model B. This is schematically shown in the right-hand side of the figure where the two models are "superimposed" and where a feature of the green aspect is shown to affect several modular units of the yellow aspect. Using the terminology of AOP, this fact is often expressed by saying that the green aspect cross-cuts the yellow aspect.
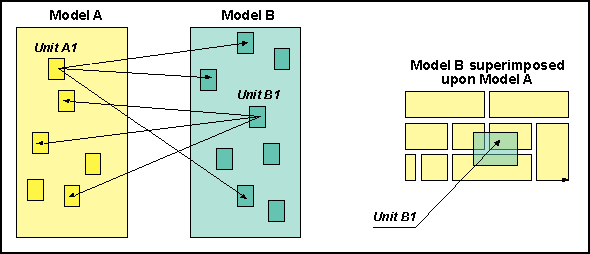
Figure 1: AspectOrientedProgramming_1
Traditional programming techniques - from procedural to object-oriented programming - have privileged the functional aspect of applications. The modelling techniques upon which they are based are targeted at modelling functional behaviour and the principle of separation of concerns is applied by organizing an application as a set of cooperating functional units (where, depending on the particular programming paradigm, a functional unit may be a procedure, a module, an object, a class, etc).
Modelling techniques have also been developed for some other typical aspects but, traditionally, it has been impossible to enforce the principle of separation of concerns with respect to more than one aspect at the same time. To illustrate, and with reference to the examples given in the previous section, consider the case of an application where both functional and error handling aspects are important and assume that the application is implemented in a class-based language such as Java or C++. In that case, the principle of separation of concerns can be applied to its functional aspect by suitably designing the classes and their interactions. It will then often be possible to localize the code that implements a particular functional requirement in a specific class (or even in a specific method of a class). This has several advantages:
Once implementation in a conventional class-based language is selected, however, it will normally be impossible to localize the code that implements the error-handling aspect of the application. Assume for instance that all application methods return an error code that indicates whether the method completed successfully or whether it encountered some error. Then, simple examples of error handling policies at component level are:
The code that implements the above policies is spread over the entire code base of the target application (or, using the standard AOP terminology, the error handling aspect cross-cuts the functional aspect). This means that changing the way the aspect is implemented (i.e. changing the error handling policy) requires global changes to the application code base. This is far more expensive and error-prone than would be the case if the implementation of the aspect were localized in a dedicated "module" (i.e. if the principle of separation of concerns were applied to the error-handling aspect as well as to the functional aspect).
The AOP paradigm provides efficient ways to express aspects and to implement specifications of aspects into application code in a manner that preserves the principle of separation of concerns. The process of modifying an existing code base to modify the implementation of a certain aspect is called the aspect weaving process. Several different AOP languages exist that implement aspect weaving in different ways. The next two sections describe two typical approaches.
At its most basic, aspect weaving can be seen as a source code transformation process and the aspect oriented language can be seen as a sort of meta-language that specifies the code transformation. AOP then becomes a form of automatic code generation where both the starting and the end code are written in the same language. This view of AOP is illustrated in the figure.
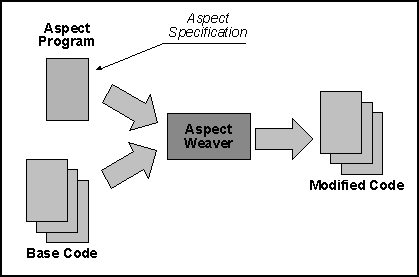
Figure 2: AspectWeavingAsCodeGeneration
The yellow boxes represent the starting code. This is organized as a set of modules. The green box represents an aspect program that defines a particular code transformation. The aspect weaver is a compiler-like program that reads the aspect program and uses it to modify the base code and automatically generate a new base code modified to implement the desired aspect. Note that both the base program and the modified base program are written in the same language.
To illustrate, consider again the previous example of implementing different error handling policies in a certain piece of code. The code on the left-hand side of the next figure represents the base code which does not implement any error handling. The error handling policy is encoded in an aspect program (not shown in the figure). After the aspect weaving process, a new modified program is automatically generated that is identical to the base program but which includes new code that implements a particular error handling policy. In the case of the figure, the error handling policy consists in checking the return code of all methods and, if this indicates an error, in commanding an application reset. The new code inserted by the aspect weaver is shown shaded in the right-hand box in the figure.
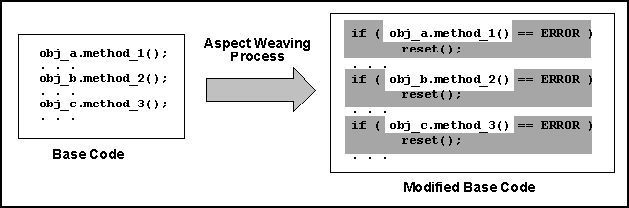
Figure 3: AspectWeavingErrorHandlingExample
The important point to note is that now error handling is encapsulated in a dedicated module (the aspect program). Changes to the error handling policy are localized to this module and can be quickly and safely implemented and then projected upon the entire base code by the aspect weaver. The principle of separation of concerns is now applied both to the functional and to the error handling aspects of the application.
The previous section proposed a view of aspect oriented programs as source code transformation. A second view of an aspect oriented program is as an extension of the compiler of the base language. This is illustrated in the next figure.
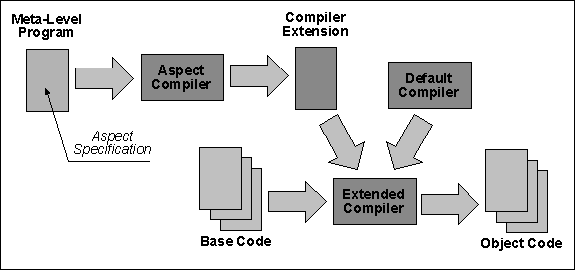
Figure 4: AspectWeavingAsCompilerExtension
The yellow boxes represent the base program written in a conventional language. The green box represents the aspect (meta-)program which specifies a new aspect that it is desired to project onto the base program. The aspect program is compiled by the aspect compiler that produces an extension to the standard compiler of the base language. This compiler extension is then combined with the base language compiler to generate an extended compiler and this is used to compile the original base program. The object code that is generated by the extended compiler encodes both the behaviour defined by the base program and the aspect defined by the aspect program.
As an example of the use of this technique, consider a base program that is
written in C/C++ and that is designed for use in a purely sequential environment
(i.e. no concurrency). Assume then that it is desired to adapt this program to
be used in a concurrent environment. This will, among other things, require
that some sections of the original code be protected against unsynchronized access
by concurrent threads of execution. Introduction of synchronization
code is a classical example of implementation of an aspect in that it requires
the same type of change to be made in many different parts of the code.
One way to simplify this task is to extend the C/C++ compiler with a new keyword
synchronized with the same semantic as the synchronized
class qualifier in Java. This would allow selected classes in the base code
to be endowed with access synchronization mechanisms. The definition of the
synchronization mechanism would be done only once and in only one location
(the meta-level program) and would then be projected onto the base code
by the extended compiler as part of the compilation process.
The AOP paradigm is comparatively new and language support is still limited but growing fast. A good overview of the AOP scene can be found at: http://aosd.net/.
Among AOP languages, the most mature is AspectJ which is targeted at Java. The AspectJ compiler and related documentation is available as public domain software from this web site: http://www.eclipse.org/aspectj/.
The success of AspectJ has spawned several attempts to port its AOP model to other target languages. Most notable among them are AspectC++, AspectC and AspectC# which, as their names imply, target C++, C and C#, respectively. All three languages are developed by academic institutions and are or will be available for free. AspectC++ is the most mature of the three but is only available as a beta version. A company, pure-systems, has recently been set up to market a plug-in for Visual Studio that implements AspectC++.
In the C++ world, arguably the most mature and effective way to do AOP is provided by OpenC++. OpenC++ was first introduced in 1995 as a source-to-source translator facilitating development of C++ language extensions, domain specific compiler optimizations and runtime metaobject protocols. It is thus not strictly speaking an AOP language but it can support aspect-oriented programming. OpenC++ is available as free open source software.
Finally, in the Automatic Control Laboratory at ETH-Zurich, work is under way to develop the XWeaver as a non-intrusive weaver for C++ code. XWeaver is non-intrusive in the sense that it minimizes the impact of the weaving process on the base code and it can produce modified code that is as readable and can comply with the same coding and documentation rules as the base code. XWeaver is therefore especially suited to the generation of code that must undergo a certification process.