Connection Design Pattern
Intent
Decouple data-processing application components from the source from which they take their inputs and from the destination to which they write their outputs.
Based On
This pattern is based on the principle of data encapsulation.
Motivation
On-board systems typically contain objects that process data: they take one or more data as inputs, they perform some operations upon them and produce one or more data as outputs. The link to the locations of their data inputs and outputs is often hard-coded. At best, some flexibility is achieved by endowing the data processing object with setter and getter methods through which some supervisory entity can set the input values and read the output values. This solution however merely shifts the problem. Additionally, it imposes an unnecessary burden on the supervisory entity that has to perform several data shuffling operations every time the data processing object is activated.
In a better solution, the link between the data processing object and its data sources and data sinks is set up as part of the object's configuration. The data processing object then becomes capable of autonomously retrieving its inputs and writing its outputs and the locations where the data are read from and written to are configuration parameters.
The connection pattern proposes a mechanism through which this reconfigurable connection between objects and their data sources and sinks can be effected.
Dictionary Entries
The following abstractions or domain-wide concepts are defined to support the implementation of this design pattern:
Structure
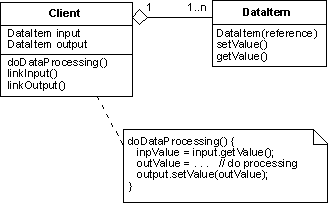
The connection pattern represents the data item abstraction through a concrete object DataItem that encapsulates an atomic data and gives read and write access to it.
Objects that need to access the atomic data do so through the data item instance. At configuration time, they are loaded with the data item instance and during normal operation they use it internally to access and update the value of the data. The loading is done through the linkInput and linkOutput methods. The name of these methods alludes to the fact that their purpose is to set up a link between a data processing object and its data sources and data sinks.
Participants
Client:The data processing component that read or update the data item value. DataItem:The concrete object that encapsulate the access to the data value.
Collaborations
The typical operational scenario for this design pattern is:
- A number of data item instances are created to encapsulate access to certain variables.
- At configuration time, a data processing component is loaded with the data item instances.
- The data processing component reads its inputs from the (internally stored) data item instances, processes them, and writes its outputs to the (internally stored) data item instances.
Consequences
- Data processing components can be written in a manner that is independent of where its inputs come from or where its outputs go to.
- Data processing components are directly responsible for managing their own data acquisition and data writing process. This relieves other components of this task.
- Access to a data item involves a level of indirection and is therefore less efficient than when the connection with the data inputs and outputs is hard-coded in the data processing components.
Applicability
This design pattern is useful when:
- It is desired to decouple data processing components from the sources from which they read their inputs and from the destinations to which they write their outputs.
Implementation Issues
How is the data item encapsulated in the DataItem object? In a C++ implementation a data item is a variable of primitive type and the DataItem object could simply be a wrapper for a pointer to the variable. The getter and setter methods then simply deference the pointer.
Data items could be set up to perform operations other than just reading and writing a value. For instance, they could attach time-stamps to written values. Or they could be made to check that the client component is authorized to access a particular data item.
The class diagram of the design pattern shows a DataItem object that gives both read and write access to the data item. Some applications will want to introduce two separate data item objects of which one offers read-only access and the second offers read-write access. The two type of data item objects would then be obtained as instances of two classes like DataItemRead and DataItemWrite of which the second is derived from the first one and adds a setter method to it.
What is the type of the data item value returned or written by the getter and setter methods in the DataItem class? Some implementations could extend the class to have several getter/setter pairs, one for each primitive type. Other might decided to have different classes, one for each primitive type. Still other implementation might opt for a single external type for data item values and the getter and setter methods then become responsible for performing the conversion between this external type and the internal type of the data item.
The pattern structure described tacitly assumes that the DataItem class encapsulates a primitive variable. The concept of data item however could be extended to cover more complex data structures such as vectors or collections of related data. A data item could also encapsulate a reference to an I/O port. This would allow uniform treatment of data stored in memory with data stored outside the processor and accessed through the I/O ports.
The structure of the design pattern assumes that DataItem is a concrete class. Clients would then normally receive an instance of this class and would have direct access to its getter and setter methods. In an alternative solution, DataItem is implemented as an abstract interface (or as an abstract class) and clients receive a reference to it. This second solution has the drawback that clients have one more level of indirection in accessing the data encapsulated in the data item but it has the advantage that it allows several types of data item classes to be created. Such different classes would be typically be useful to encapsulate different types of atomic data.
The crucial considerations in implementing the data item concept is likely to be the efficiency of the access to the data encapsulated in the data items. If DataItem is realized as concrete class with non-overridable methods, then its getter and setter methods can be declared inline.
OBS Framework Mapping
The implementation of this design pattern in the OBS Framework is supported by the following classes:
- Data Itemcomponent -->
DC_DataItem
Sample Code
As a first example, consider an application where all variables are of integer types. The DataItem class can then be defined as follows:
class DataItem {
int* var; // variable behind the data item
DataItem(int* var) { // constructor
this->var=var;
}
int getValue() {
return *var;
}
void setValue(int newValue) {
*var = newValue;
}
}
Consider the case of a component procComponent that processes one input and produces one output. This component would be configured as follows:
int input; // the input variable
int output; // the output variable
. . .
DataItem dpInp(&input);
DataItem dpOut(&output);
. . .
procComponent.linkInput(dpInp);
procComponent.linkOutput(dpOut);
Note that the processing component receives a copy of the data item objects. This allows it to directly call their getter and setter methods.
If the application needs to handle several different types of data items but data processing components only need to see one single data type, one solution is to have a DataItem class with several constructors, one for each possible data item type. Consider for instance the situation where some data types are integers (32 bits) and others are short integers (16 bits) but where data processing components can be made to deal exclusively with 32-bits integers. In that case, the DataItem class can be defined as follows:
class DataItem {
int* var32;
short* var16;
bool typeFlag;
DataItem(int* var) { // constructor
var32=var;
typeFlag=true;
}
DataItem(short* var) { // constructor
var16=var;
typeFlag=false;
}
int getValue() {
if (typeFlag)
return var32;
else
return (int)var16;
}
void setValue(int newValue) {
if (typeFlag)
var32 = newValue;
else
var16 = (short)newValue;
}
}
The implementation of the getter and setter methods uses the value of the typeFlag decide which of the two representation to use. This introduces some overhead in the data access. An alternative solution would be to have a base DataItem class that deals with 32-bits integers (assumed to be the default) but with getter and setter methods defined virtual. This class could then be subclassed and its setter and getter methods could be redefined to handle 16-bits integers.
This second solution simplifies the implementation of the getter and setter methods and removes the need for an if clause as in the last example but it introduces two other kinds of overheads:
- the getter and setter methods are virtual and therefore calling them involves a level of indirection (note that if DataItem is a non-extensible concrete class, then its getter and setter methods can be declared as inline methods which would increase the efficiency of their usage)
- the data processing clients must now be given references to the data item objects which introduces one further level of indirection in the access to their methods.
Remarks
None
Author
A. Pasetti (P&P Software)
Last Modified
2002-06-22